最近在用 redux 编写前端业务逻辑的时候,一直在思考对于同一个页面的业务,如何定义 store 的数据结构可以简化其操作。
普通程序员关心的是代码,优秀的程序员关心的是数据结构和它们之间的关系。 – linus
1.store 的组织结构
一般的,redux 最上层 的 store 应该是一个树对象,这棵树又由很多 reducer 函数返回的子 store 对象组成。通常,我会根据页面去划分不同的 reducer,在有些业务场景下,全局 store 可能还需要初始为某个具体对象。
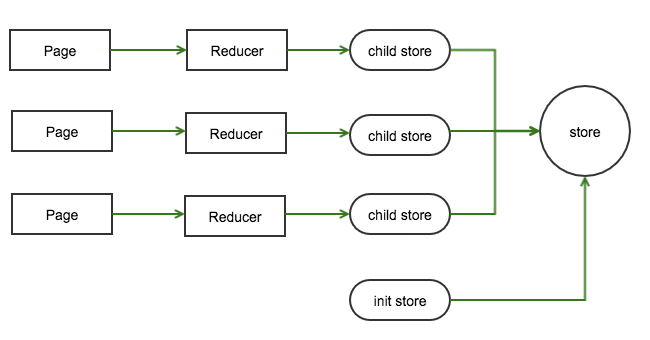
从上图可以看出,合理组织 child store 的数据结构可以简化对应 reducer 计算以及相应的 action。
2.child store 的数据结构
child store 是一个包含若干属性的对象,属性值可以是任意值,对 child store 的操作成本主要集中在复杂属性值,比如数组与普通对象。
3.对 child store 的操作
对于数据源,前端页面更关心:
- 要展示的数据源从哪来
- 触发某个
action后,页面数据会发生什么变化
对应到 child store,无非是对其进行增删改查四个操作,同时要区分是对一组数据的批量操作,还是对单条数据的单独操作。无论何种操作,要想快速完成,首先得快速定位操作的数据源位置,即 child store 的数据结构要便于快速搜索数据。
4.数据扁平化
数据扁平化由数据库扁平化衍生而来,原指根据一系列所谓的标准形式重构关系型数据库,以减少数据冗余和提高数据完整性的过程。
在前端应用中数据扁平化多用于将层级深,嵌套复杂的对象属性及值提取出来形成一个新对象,考虑一个简单的嵌套例子:
|
|
再看一个更具体的例子:
blogList 包含了每篇文章的基础信息以及其作者的全部信息,如果要根据 id 查找某篇文章的信息,就必须执行如下语句:
观察上面的查找语句,可以发现查询一篇 blog 需要花费时间复杂度为 O(n),而且作者的基础信息冗余在了 blog 中,如果要查找某个作者信息就不得不通过其写的文章信息。对于查找文章及其信息的功能,扁平化后的数据结构如下:
扁平化文章列表之后,根据 id 查找某篇文章只需要花费 O(1) 的时间,而且将作者信息从文章信息中提取出来,避免两者冗余, 同时又没有损失数据完整性。
总结下来,数据扁平化常见的做法是对复杂的数据结构作如下处理:
- 提取层级较深的属性及其值,避免嵌套很深
- 合理分离不同的数据对象,防止数据的冗余
- 保证数据的完整性,避免数据信息的损失
5.普通对象和数组操作
|
|
观察上述代码可知:
- 如果需要根据某个字段的值来获取具体的数据,并且该字段又是源数据集的某个属性(blogObj 的 key,blogArr 的 indice),那么搜索普通对象和数组的时间复杂度均为
O(1) - 如果需要根据某个字段的值来获取具体的数据,但是该字段不是源数据集的属性( title ),那么搜索普通对象和数组的时间复杂度均为
O(n) - 如果需要遍历源数据集,普通对象和数组花费的时间复杂度均为
O(n) - 从普通对象和数组本身数据结构看,普通对象更像一张哈希表,通过某个属性的具体值去计算对应的数据;而数组更像一张顺序表,在遍历的过程中,可以保证数据访问的顺序性
- es6 后,数组有很多自带的操作方法如
forEach,map,reduce等可以提升开发者的编码效率,而普通对象如果想使用这些方法,则必须通过Object.keys,Object.values等方法来转换成数组,这么做的副作用是会增加时间复杂度,并且无法保证对象属性遍历的顺序性
以上结论比较粗浅,不一定适用于其他复杂的数据结构,针对以上博客文章的数据集,如果业务中既有遍历文章数组的要求,又有需要通过文章 id 快速访问对应文章信息的需求,更好的数据结构如下:
更复杂的例子,参考 Normalized State